最前
作为一名英语并不好的小白,近期苦于阅读英文文献,常常要用到机器翻译。然而,从 PDF 文件中复制内容,往往会出现多余的换行情况,强迫症患者表示这很难受,如下图所示:
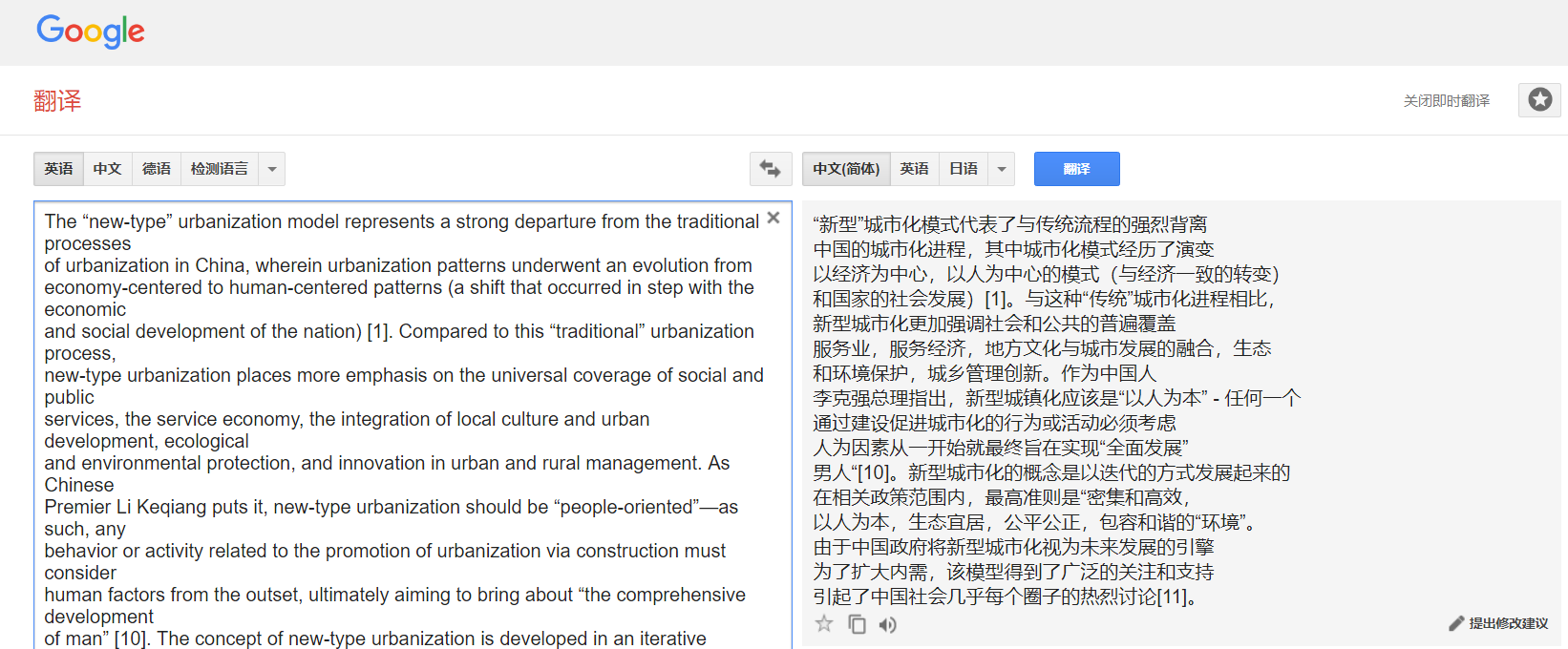
并且这样多余的换行出现一定程度上影响了翻译的结果,也不利于中文阅读,影响看论文的速度,
解决方案
1. 利用 Python 将多余的换行去除掉
该功能参考了 CSDN 作者 YLPGG 的思路,使用时仅需复制需要翻译的内容到程序中,可复制多段文字,然后在内容后输入一个#(井字符号),再回车即可,代码如下:
1 | def get_content(): |
2. 利用 Python 访问 API 获取翻译结果,代码如下:
2.1 百度翻译 API
使用前需在百度翻译开放平台 注册开发者账号,每个月有 200w 字符的免费翻译额度,超出后按照 49 元 / 百万字符支付当月全部翻译字符数费用,应该个人使用 200w 字符是够用的,论文狂魔除外。
1 | def get_translation(q): |
其它翻译 API 待更新
最后
已知 Bug
由于识别段落换行和多余换行区别的局限性,如果正巧某行文字的最后一个字符为“.”(英文句号),则会被认为是正常的段落换行,导致分段错误,但不影响句子的完整性。
部分英语文献中可能含有特殊字符,会导致翻译 API 返回错误,在程序中会被直接跳过,但大部分正常文献都没有问题。
下载链接
我的 GitHub:https://github.com/busbyjrj/translate
最近更新时间:2018 年 8 月 12 日